Cross Site DAG / DAC Mode – Scenarios
Here is a scenario where in we have a cross site DAG and we have the core discussion on how it works during a disaster (WAN down , Primary site down).
So please go though this and post me with your feedback and corrections if any,
If you wish to add more to this please feel free to add to it
Environment:
Two Sites
Primary – 10 database and copies
2 CAS/HUB
5 MBX – 1 witness
DR – Copies
5 MBX and 2nd witness (alternate witness)
2 CAS/HUB
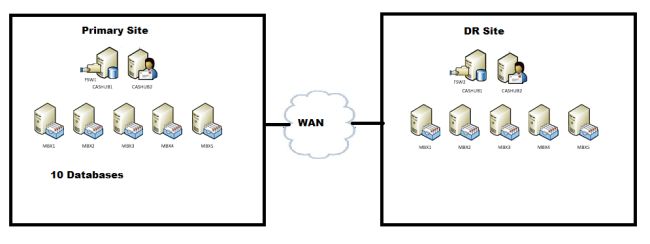
1 DAG – 10 Databases
Research:
Primary Site:
2 CAS/HUB – Primary Witness
5 MBX – 1 witness
Secondary Site:
5 MBX and 2nd witness (Alternate witness)
2 CAS/HUB
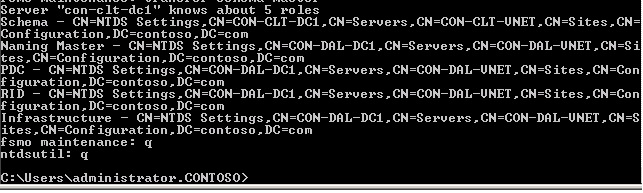
Based on the current deployment where we have 2 sites and identical number of nodes (cluster-wise) on both sides, what would happen if the link goes down while servers are still up?
Scenario 1: You have two sites and the WAN link between the sites goes down,
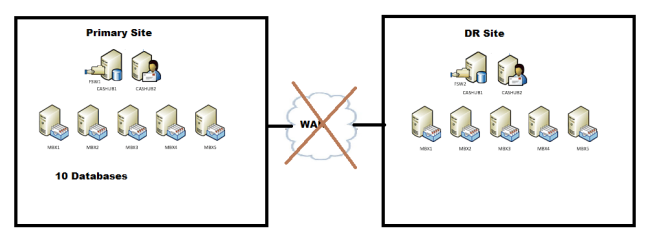
One DAG with 10 members and 10 databases,
WAN link between the sites goes down (DAC doesn’t come into picture)
- Once when the WAN link goes down, the communication between the sites are disrupted.
- As a result the Secondary DR Site will loses its quorum and will not be able to continue,
- Primary site still can maintain a quorum as it has 6 votes (5 Nodes + 1 FSW). (Node and File Share Majority)
- Also the databases which were active in the DR site will be failed over to Primary site based on the preferences, which will be taken care by PAM (primary active manager) active on the Primary site.
Note: If AD replication between the sites are fine, then the databases will be failed over to the primary site, else database will be dismounted on the DR site and we need to manually use the command to mount them on the Primary site,
Move-ActiveMailboxDatabase <Database Name> -ActivateOnServer <target server>
- Now the DAG is completely operational.
- If the WAN link comes back online, then a manual interruption is required to restore the services again, like moving the active database copies to the DR site.
Scenario 2:
a. Primary Site goes down – DAGONLY (Dac mode is turned on)
Datacenter Activation Mode is a mode specifically for multisite Data Availability Groups with 3 or more members.
It is there to stop datacenter DAG split brain syndrome with the help of a protocol called “Datacenter Activation Coordination Protocol (DACP)”
DAC operates this using literally a bit that it flips 0 or 1. “0” meaning it cannot mount a database and upon talking to other DAG members using DACP and finding another server with 1, will mount the databases as it knows it is allowed to.
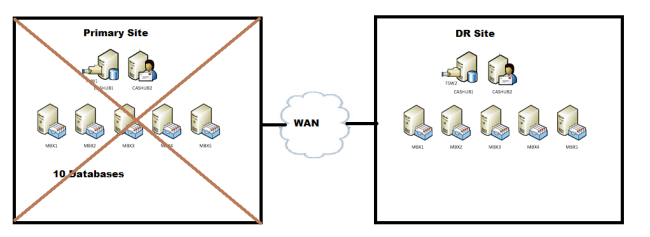
- Now the Primary site is down due to some reason, it has lost its quorum.
- As the Dag is not operational, hence a datacenter switchover is required
- Steps involved in Datacenter switchover,
- Stop the primary site,
Stop-DatabaseAvailabilityGroup -Identity DAG1 -ActiveDirectorySite <Primary Site> –ConfigurationOnly
5. Stop DAG members,
Stop-DatabaseAvailabilityGroup -Identity DAG1 -MailboxServer <DAGmembersinPrimarySite> –ConfigurationOnly
6. Restore Dag on the DR site using the following command,
Restore-DatabaseAvailabilityGroup -Identity DAG1 -ActiveDirectorySite <DR Site> -AlternateWitnessServer <HUBServer> -AlternateWitnessDirectory <WitnessDirectory Path>
The Restore-DatabaseAvailabilityGroup cmdlet performs several operations that affect the structure and membership of the DAG’s cluster. This task will:
- Forcibly evict the servers listed on the StoppedServersList from the DAG’s cluster, thereby reestablishing quorum for the cluster enabling the surviving DAG members to start and provide service.
- Configure the DAG to use the alternate witness server if there is an even number of surviving DAG members.
7. Mount the database on the DR Site,
Move-ActiveMailboxDatabase -Server <DAGMemberinPrimarySite> -ActivateOnServer <DAGMemberinDRSite> -SkipActiveCopyChecks –SkipClientExperienceChecks –SkipHealthChecks -SkipLagChecks
Scenario 3:
- b. Primary Site goes down –(Dag mode is turned OFF)
When the DAG isn’t in DAC mode, the specific actions to terminate any surviving DAG members in the primary datacenter are as follows:
- The DAG members in the primary datacenter must be forcibly evicted from the DAG’s underlying cluster by running the following commands on each member:
net stop clussvc
cluster <DAGName> node <DAGMemberName> /forcecleanup
- The DAG members in the second datacenter must now be restarted and then used to complete the eviction process from the second datacenter.
Stop the Cluster service on each DAG member in the second datacenter by running the following command on each member:
net stop clussvc
- On a DAG member in the second datacenter, force a quorum start of the Cluster service by running the following command:
net start clussvc /forcequorum
- Open the Failover Cluster Management tool and connect to the DAG’s underlying cluster. Expand the cluster, and then expand Nodes. Right-click each node in the primary datacenter, select More Actions, and then selectEvict. When you’re done evicting the DAG members in the primary datacenter, close the Failover Cluster Management tool.
When the DAG isn’t in DAC mode, the steps to complete activation of the mailbox servers in the second datacenter are as follows:
- The quorum must be modified based on the number of DAG members in the second datacenter.
If there’s an odd number of DAG members, change the DAG quorum model from a Node a File Share Majority to a Node Majority quorum by running the following command:
cluster <DAGName> /quorum /nodemajority
- If there’s an even number of DAG members, reconfigure the witness server and directory by running the following command in the Exchange Management Shell:
Set-DatabaseAvailabilityGroup <DAGName> -WitnessServer <ServerName>
- Start the Cluster service on any remaining DAG members in the second datacenter by running the following command:
net start clussvc
- Perform server switchovers to activate the mailbox databases in the DAG by running the following command for each DAG member:
Move-ActiveMailboxDatabase -Server <DAGMemberinPrimarySite> -ActivateOnServer <DAGMemberinSecondSite>
- Mount the mailbox databases on each DAG member in the second site by running the following command:
Get-MailboxDatabase <DAGMemberinSecondSite> | Mount-Database
More information on DAC:
How DAC mode works : http://technet.microsoft.com/en-us/library/dd979790(v=exchg.141).aspx
Understanding DAC : http://technet.microsoft.com/en-us/library/dd351049.aspx
Regards,
Ganesh G